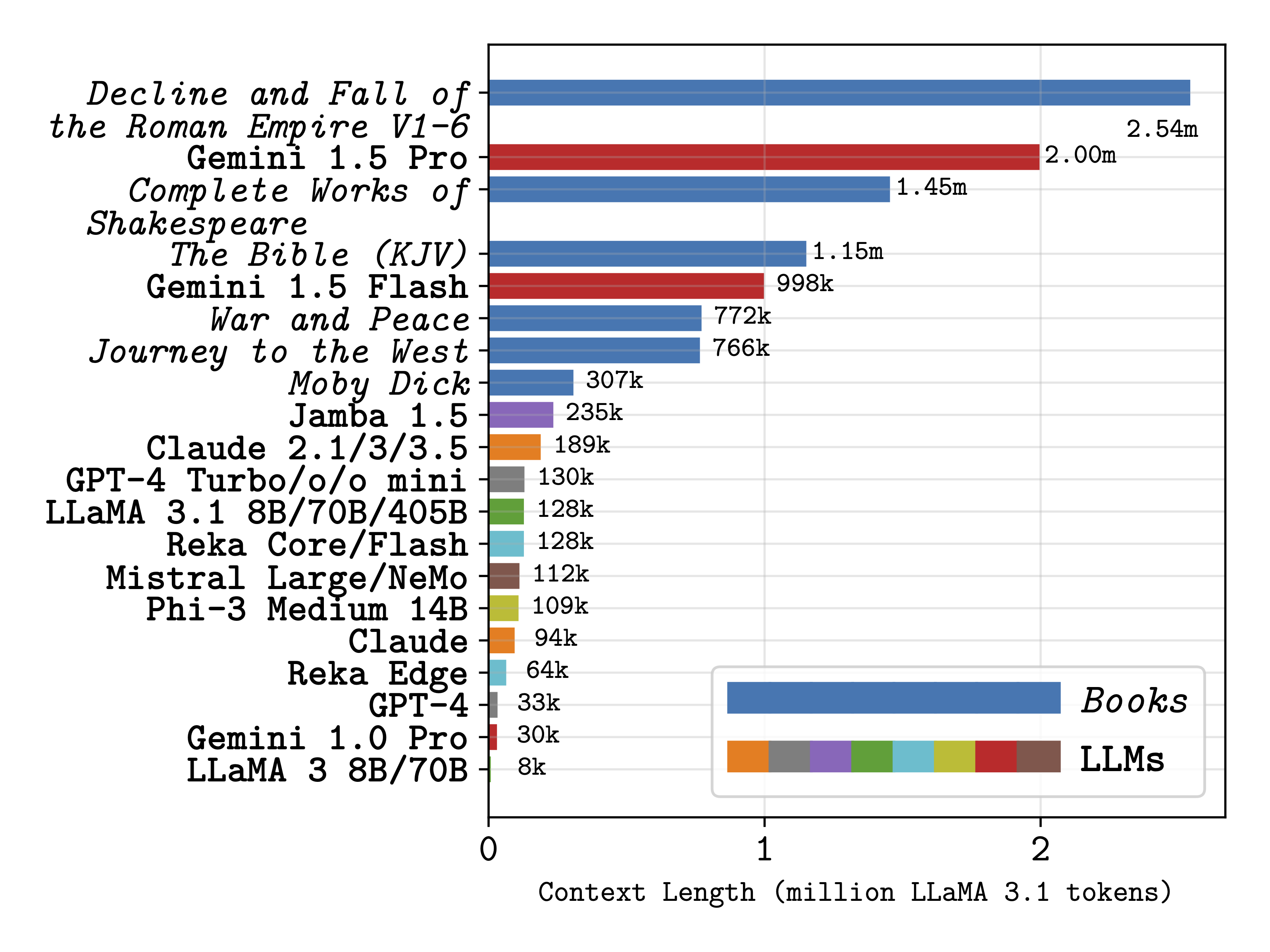
Contextualising LLM context limits (books sources from Project Gutenberg). Frontier long-context LLMs have context limits that can contain multiple books simultaneously.
Overview
As the context limits of Large Language Models (LLMs) increase, the range of possible applications and downstream functions broadens. Although the development of longer context models has seen rapid gains recently, our understanding of how effectively they use their context has not kept pace. To address this, we conduct a set of retrieval experiments designed to evaluate the capabilities of 17 leading LLMs, such as their ability to follow threads of information through the context window. Strikingly, we find that many models are remarkably thread-safe: capable of simultaneously following multiple threads without significant loss in performance. Still, for many models, we find the effective context limit is significantly shorter than the supported context length, with accuracy decreasing as the context window grows.
Needle Retrieval Tasks
Our evaluation consists of the following 6 retrieval-based long-context experiments ranging from simple single needle retrieval to challenging multi-thread retrieval. We carry out our experiments in an abstract UUID key-value setting at context lengths ranging from 1.2k to 630k tokens.

Experiments
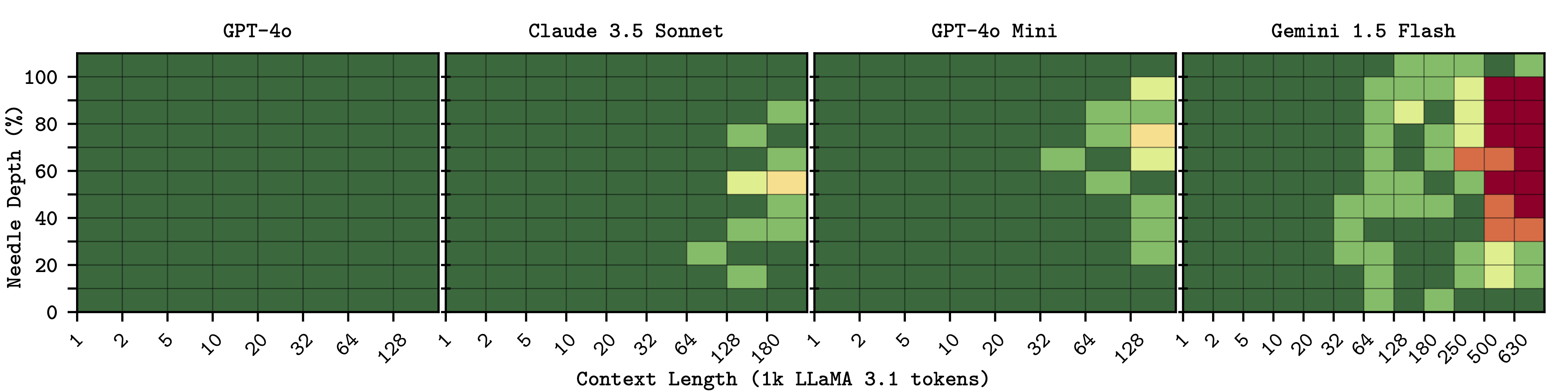
Single Needles - for most models, retrieval precision decreases towards the middle of the context window.
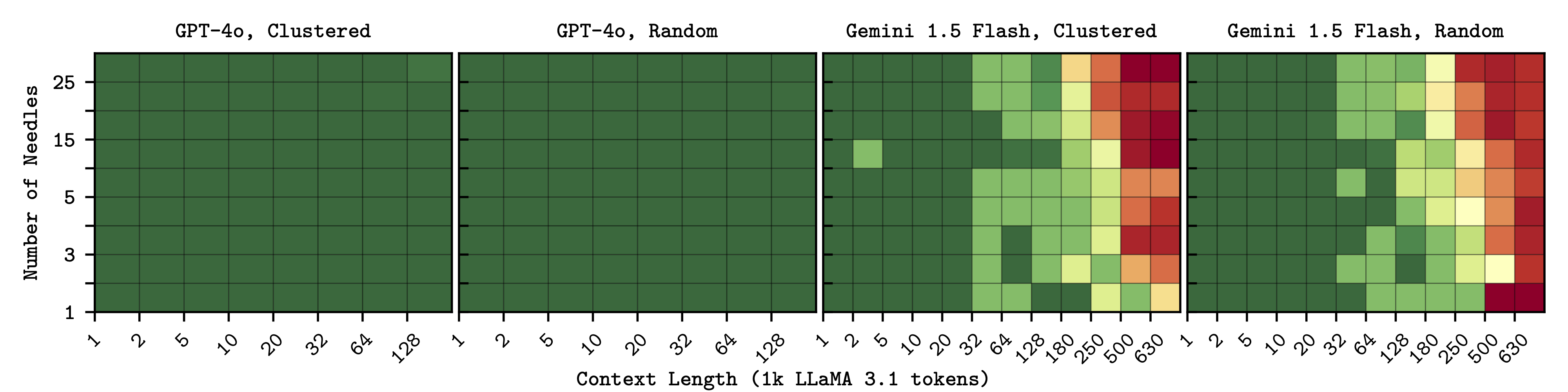
Multiple Needles - context length has a substantially greater effect on performance than needle placement or number.
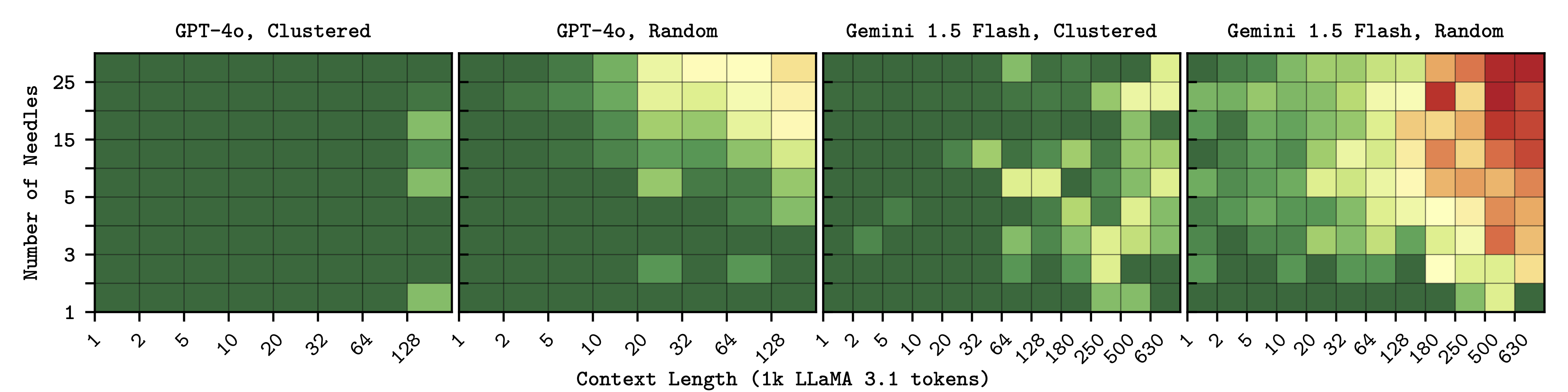
Conditional Needles - needles prove easier to retrieve when clustered.
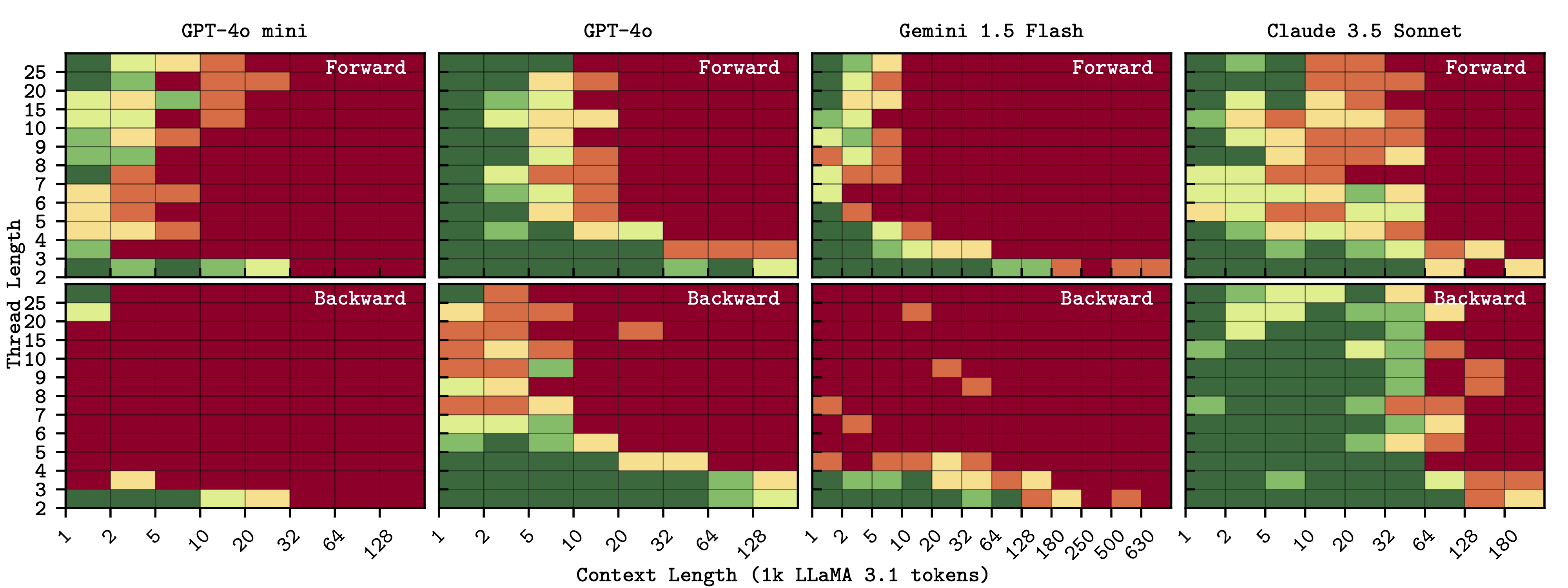
Threading - for most models, forward-travelling needles are easier to follow.
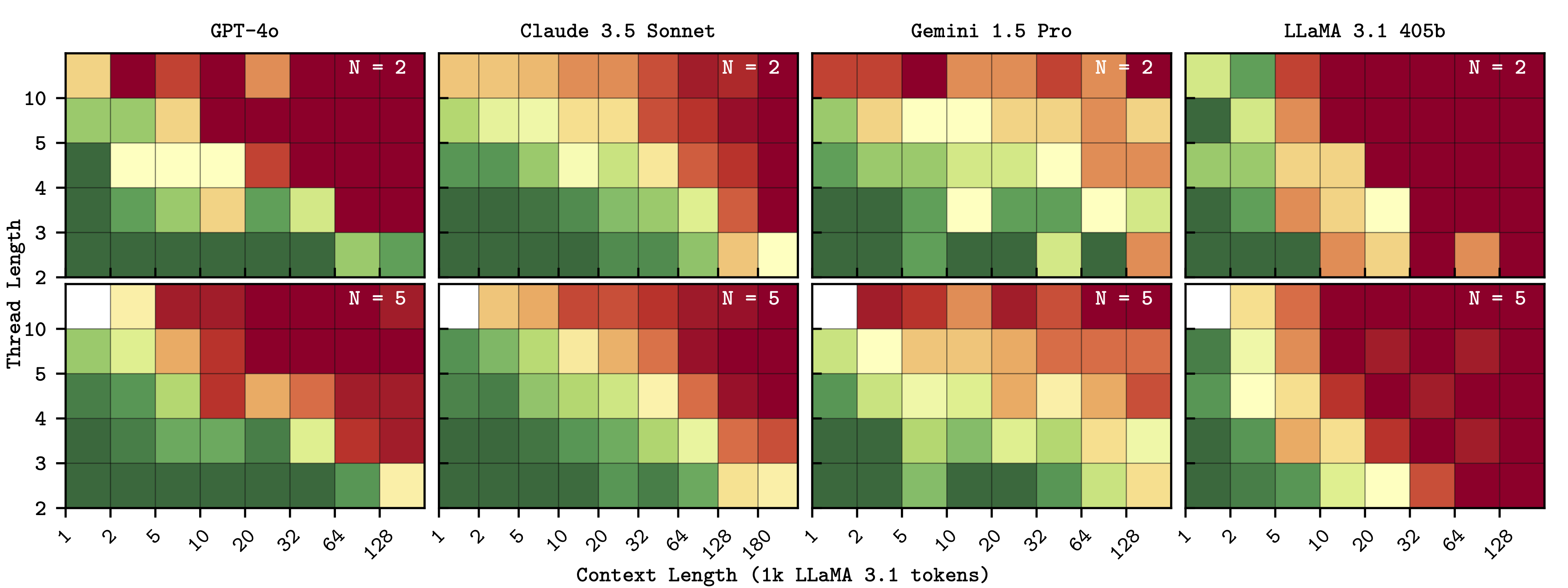
Multi-Threading - concurrently following N threads does not significantly degrade performance.
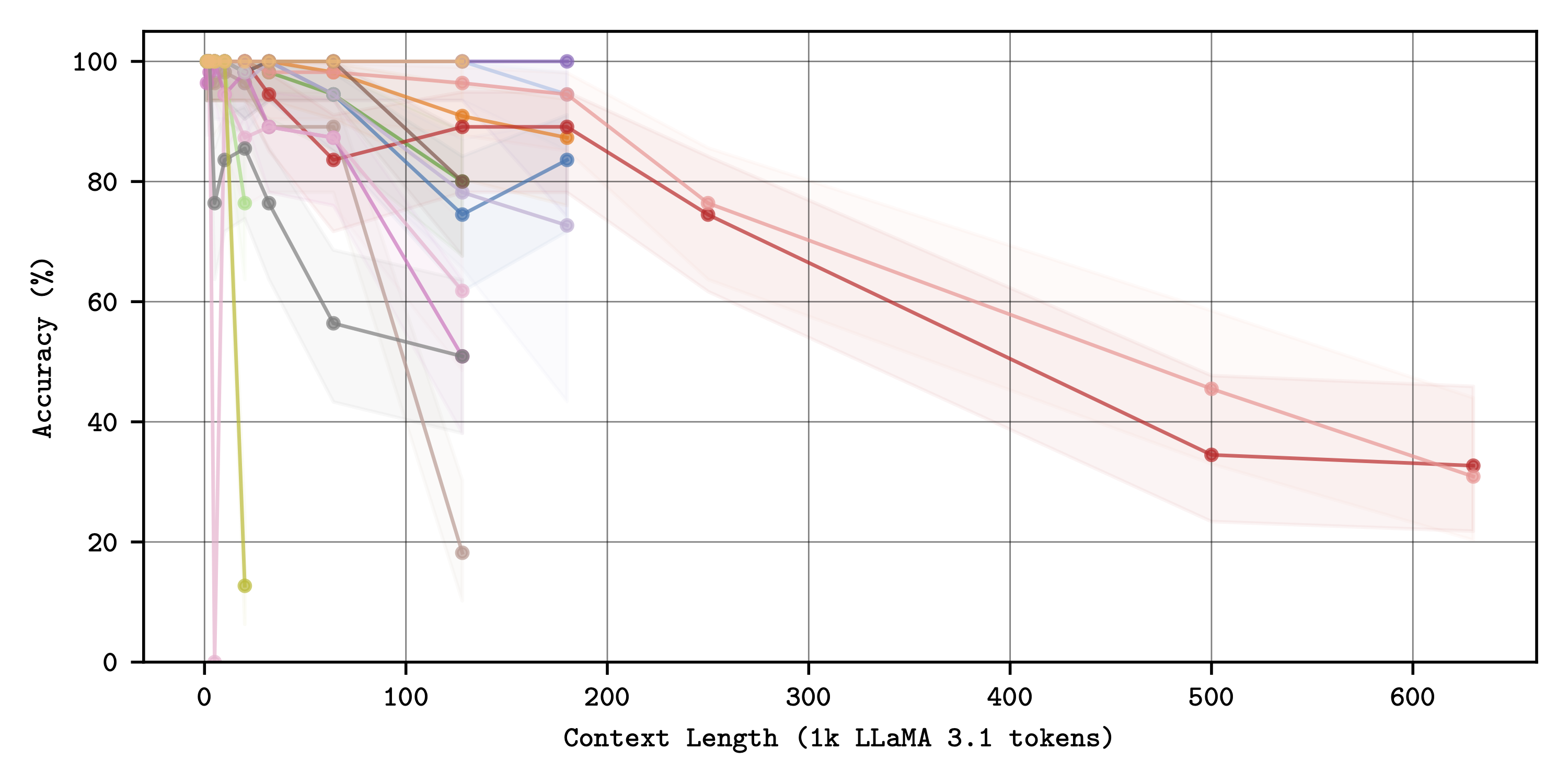

Single Needles
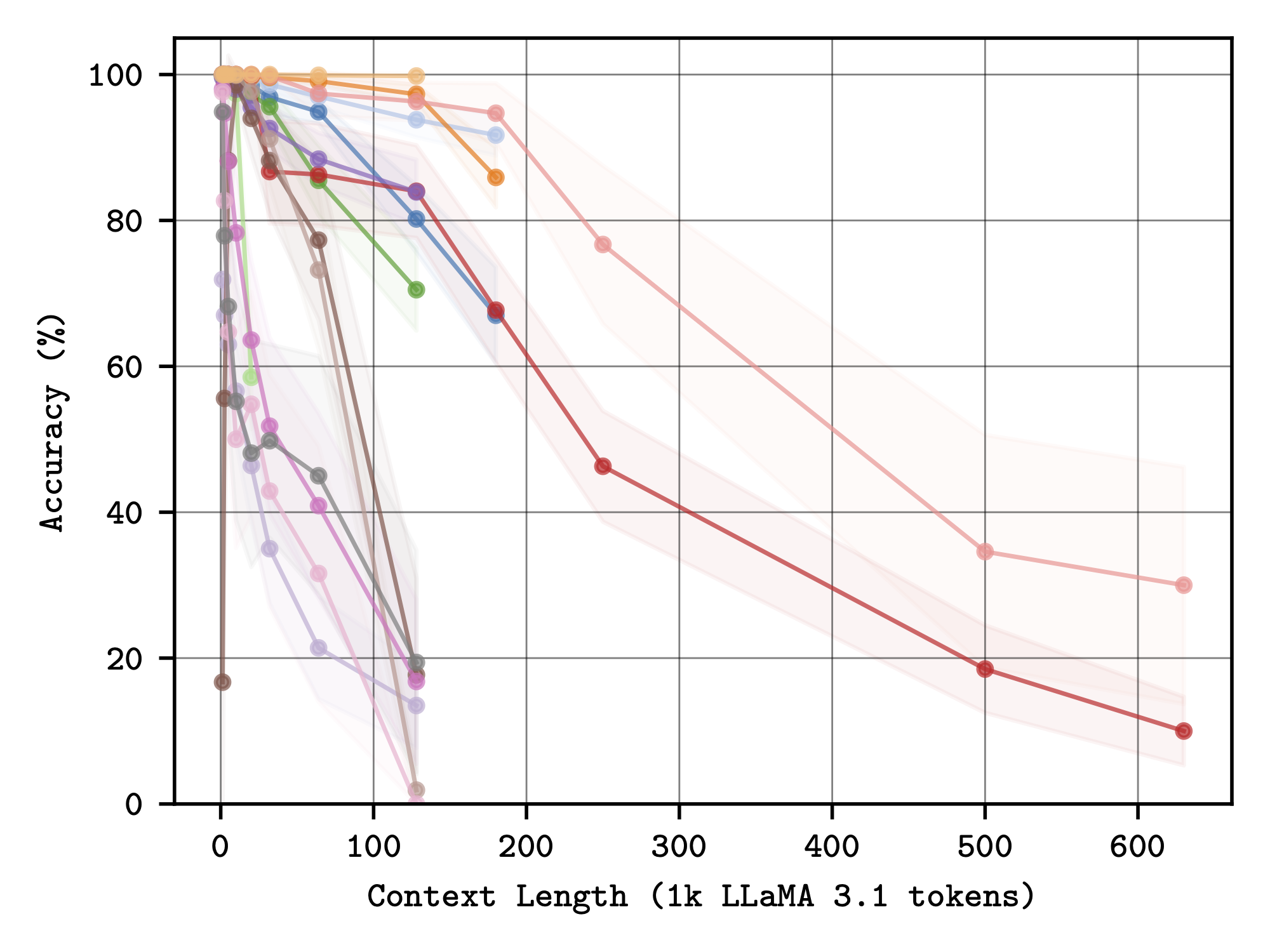
Multiple Needles
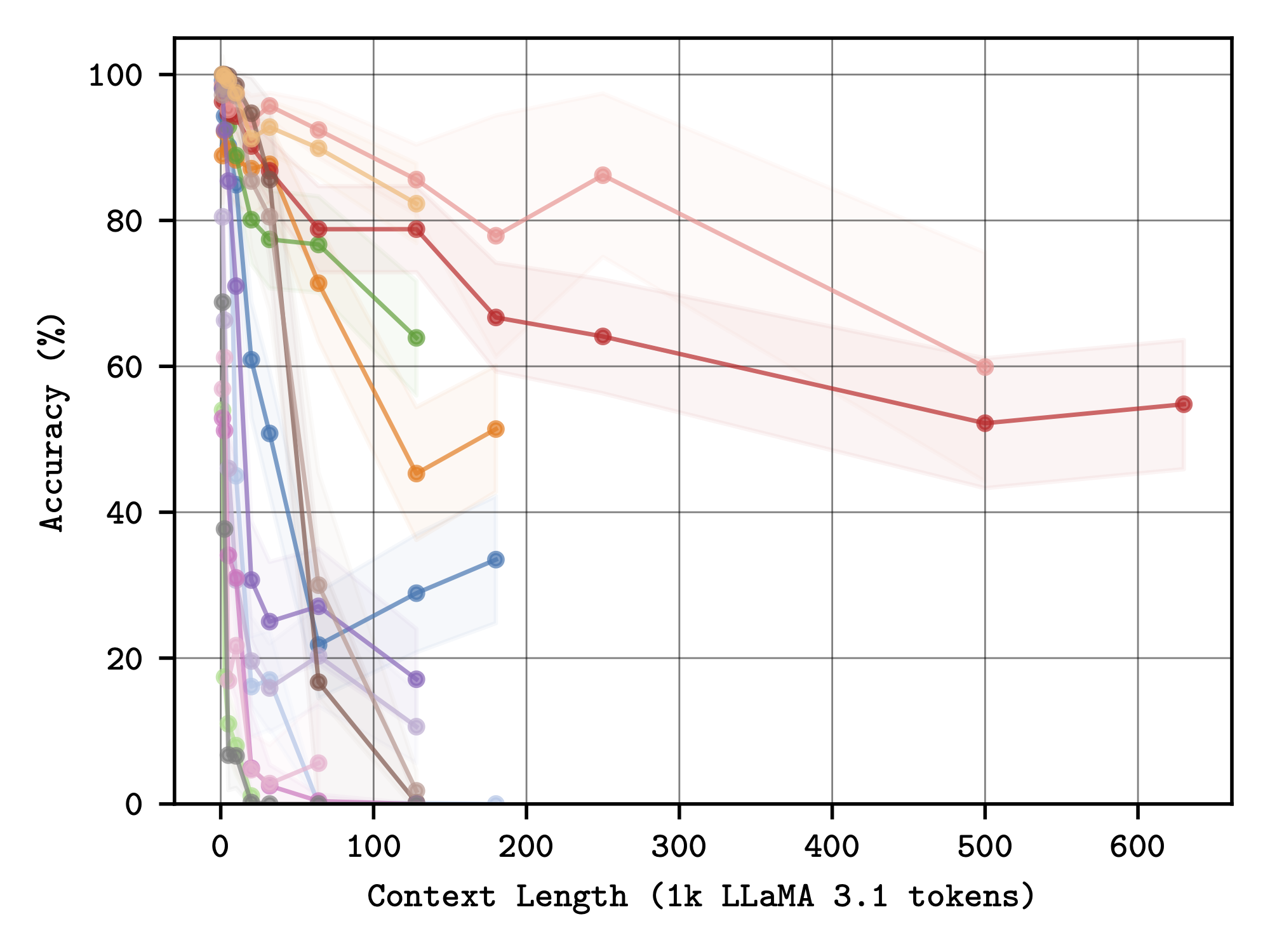
Conditional Needles
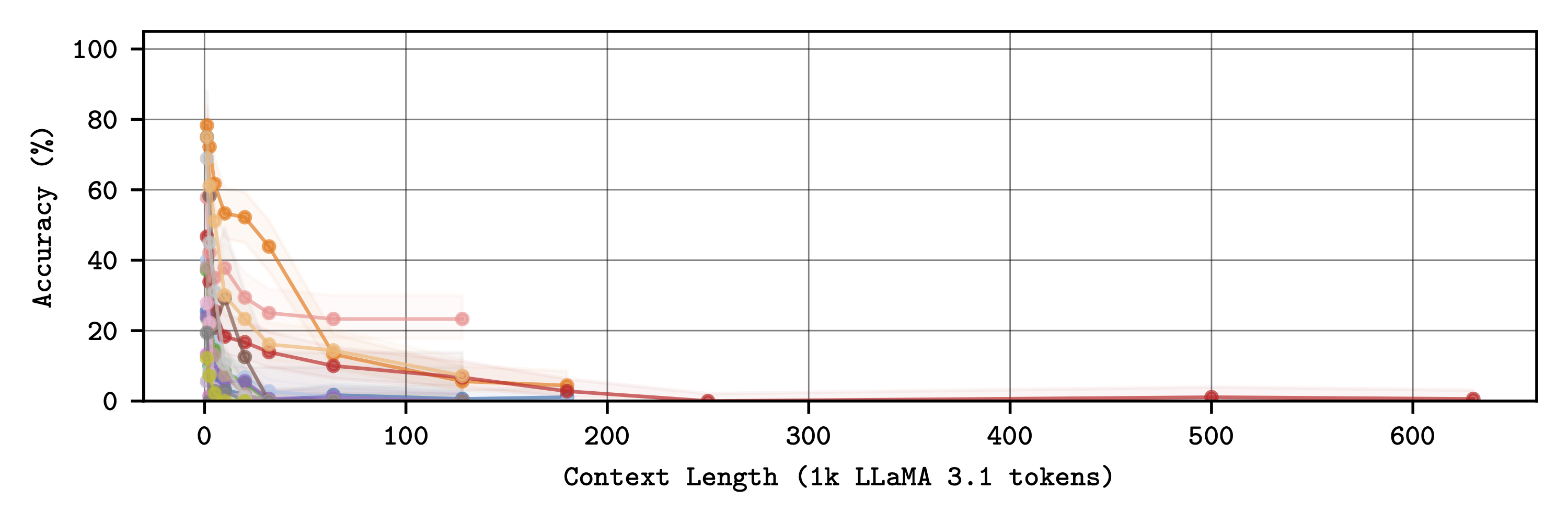
Threading
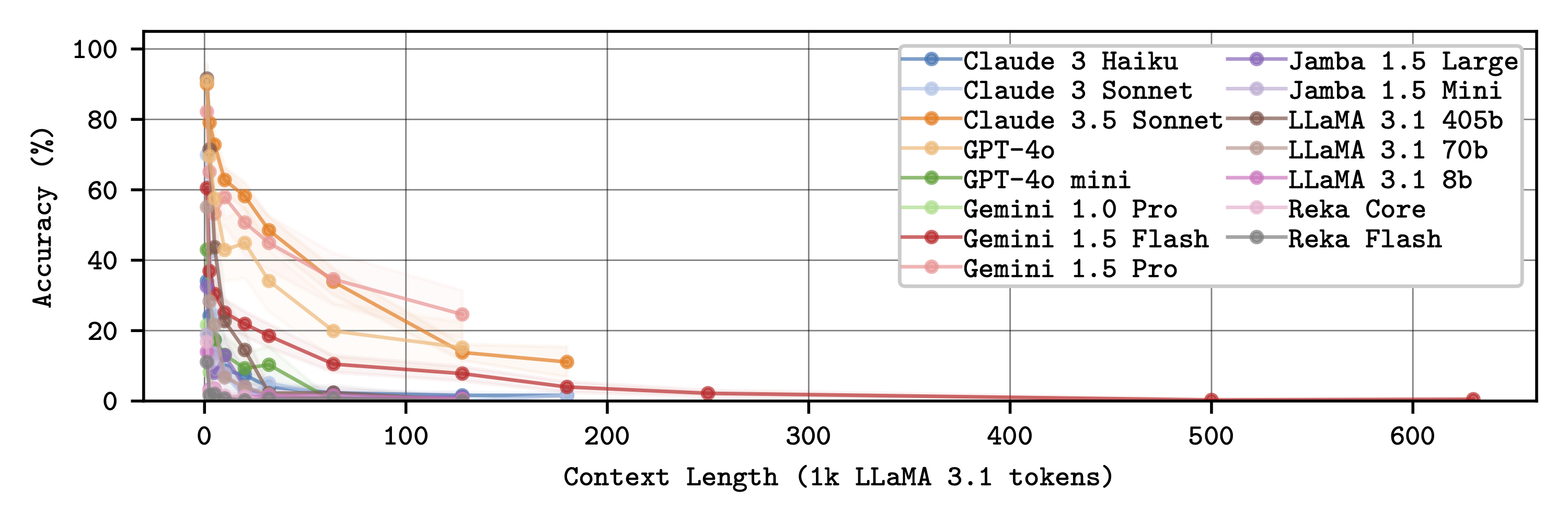
Multi-Threading
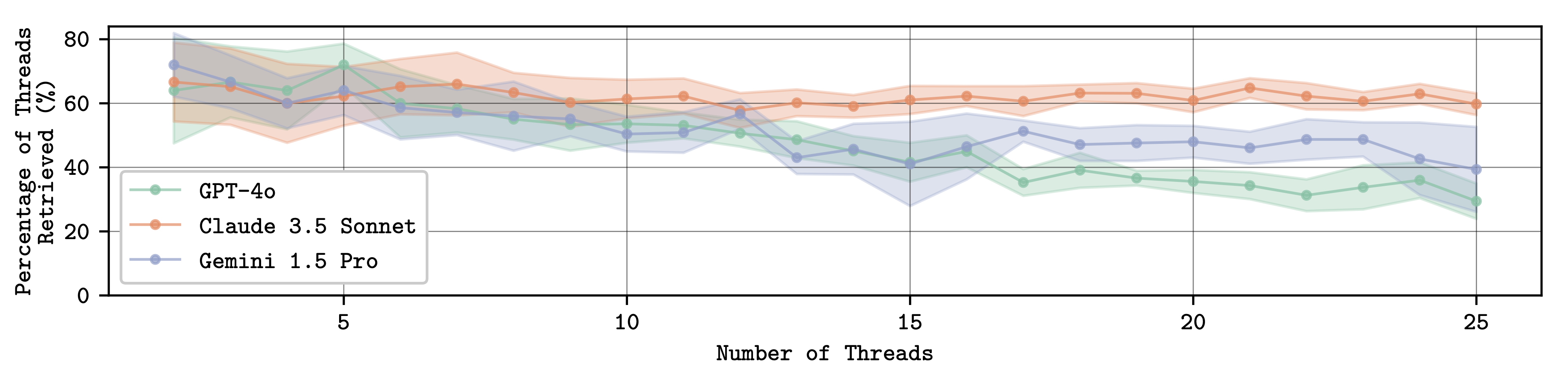
Frontier LLMs are thread-safe. Each point represents an average over 10 repeats retrieving randomly directed threads with a length of 3 in a 20k token haystack.
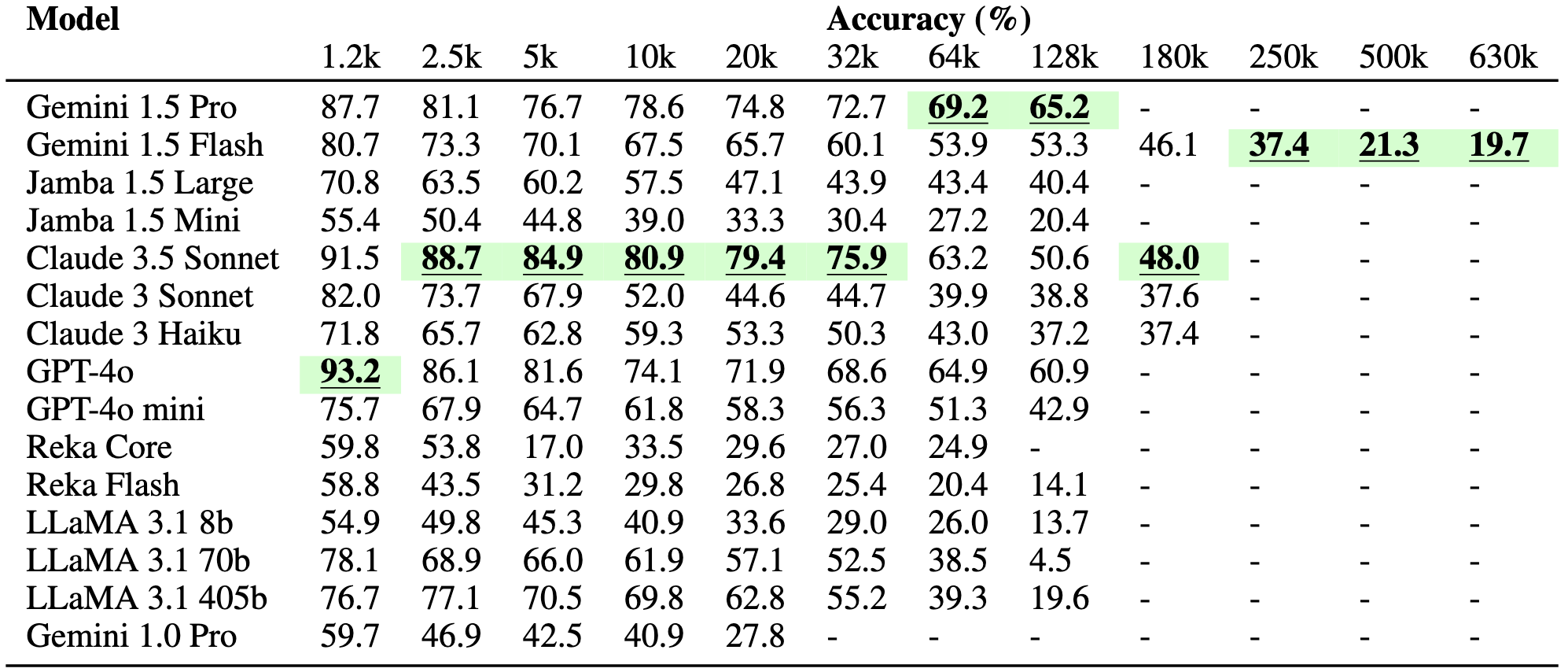
Aggregated results across 5 tasks. The highest scoring model at each context length is highlighted.
Effective Context Limits
We use contours at selected thresholds to visualise a task-specific effective context length for each model.
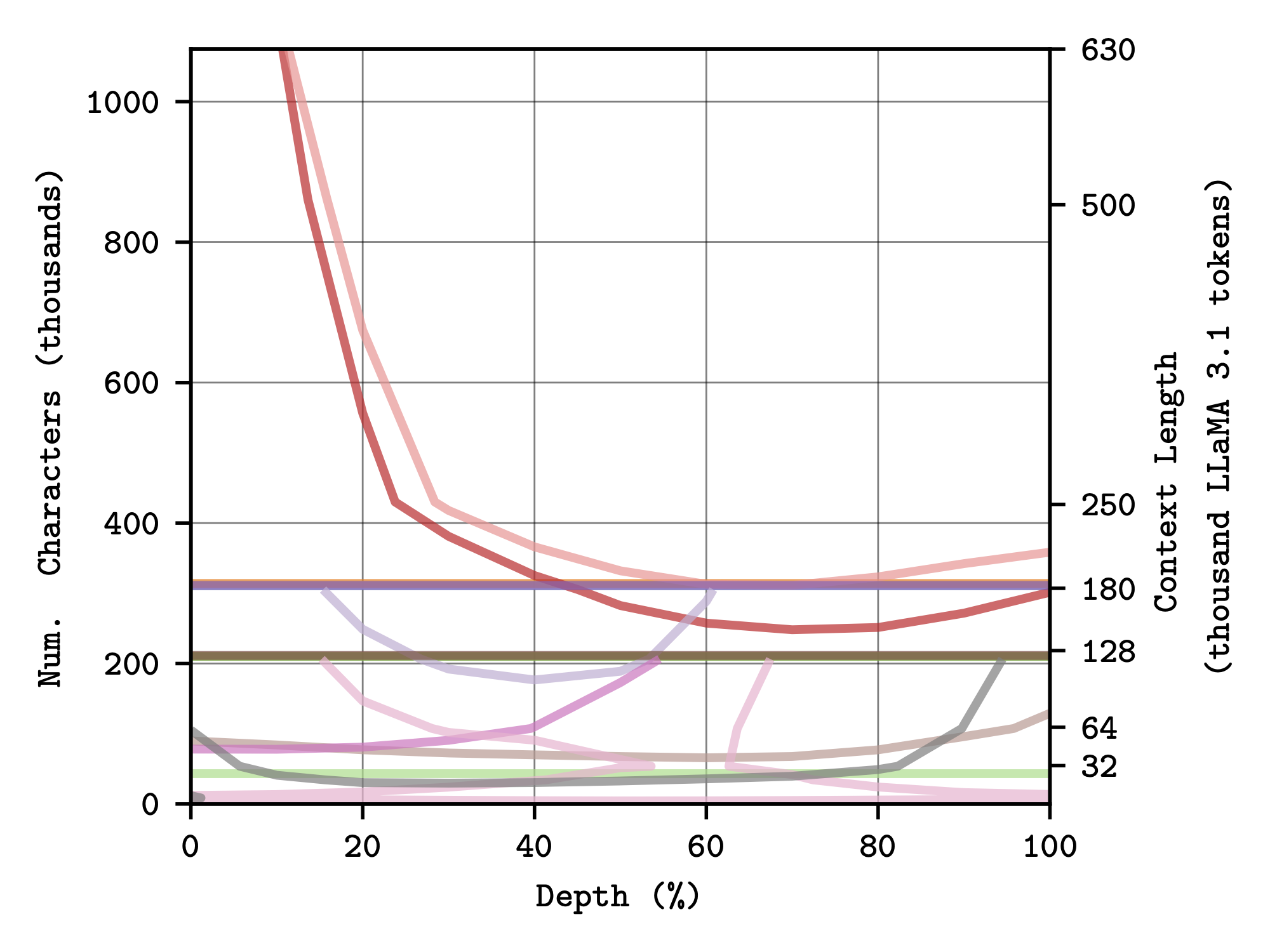
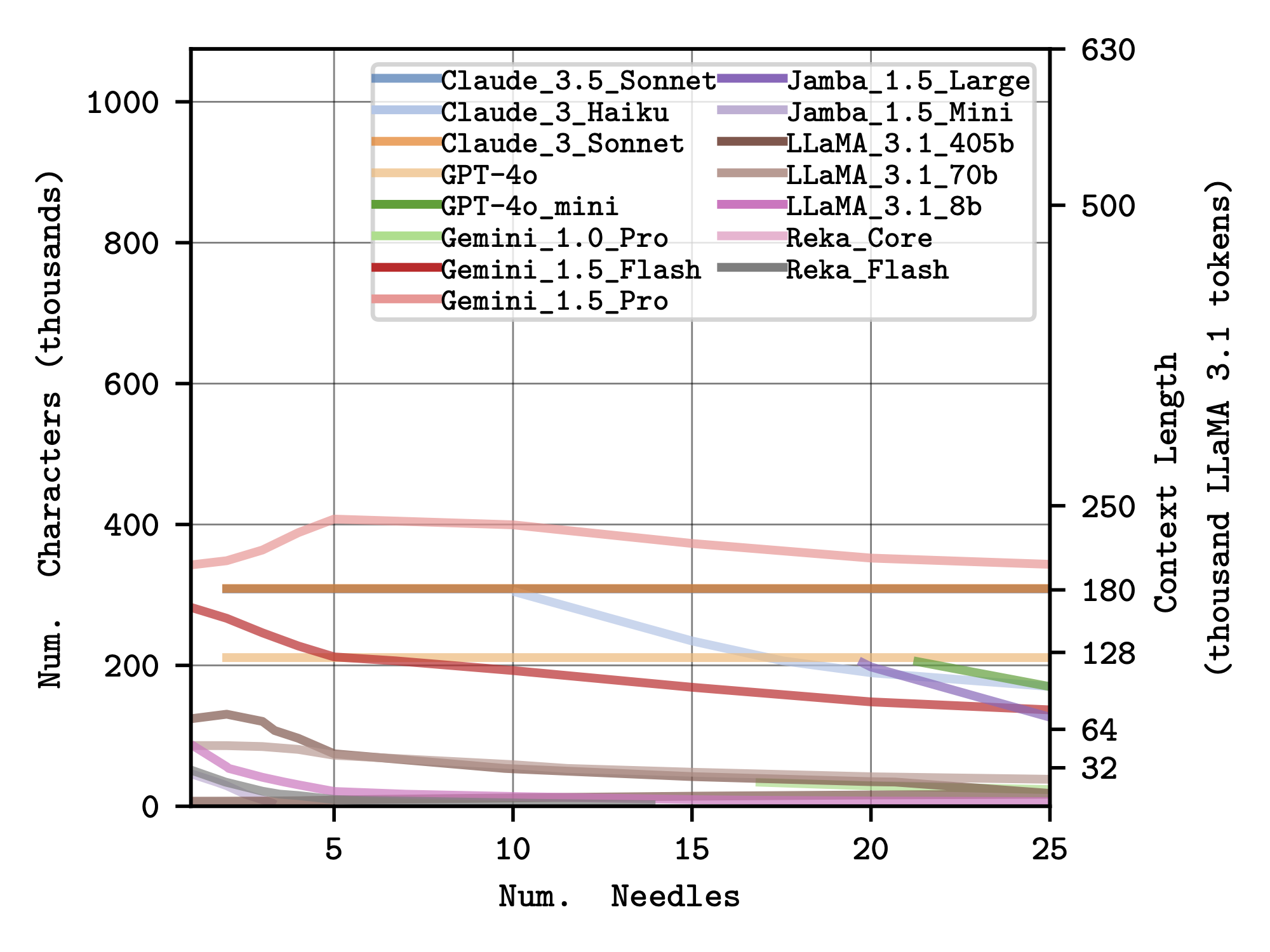
Effective context lengths for the Single Needle (left) and Multiple Needles (right) tasks.